





It can be rewarding and productive to interact with an AI chatbot for certain tasks, like...
tl;dr
- Building custom AI chatbots has become really easy.
- Getting those chatbots up to production-quality is much harder.
- We have many levers of control, but the reality is that we can’t predict their impacts.
- Without a good system for evaluation and QA, we can’t even tell whether our changes are making things better or worse.
- Jump down to Developing systems for evaluation and QA to learn about a straightforward approach that has worked for us.
- But also see An important lesson: Improvement is really hard! for some helpful expectation-setting.
<- Previous article in series: "Beating the mean: beyond chatbots"
<-- Start at the beginning: "Beating the mean: introducing the series"
Introduction
It’s really easy to produce an AI chatbot these days. There are plenty of no-code options, like OpenAI’s GPTs or Hugging Face’s Assistants, and developer options aren’t much harder, with resources like OpenAI’s friendly API, their cookbook, and the LangChain library to build upon. Proofs of concept (POCs) are quick to build and can appear astonishingly capable — but they’re definitely not perfect. So the next step is to find and assess their imperfections, separate the tolerable ones from the intolerable ones, and go about revising your way toward a quality that can meet your needs in production. This turns out to be quite a lot harder.
In this post, I’ll discuss the approach that we took as we evolved a promising POC for research and evaluation assistance into a reliable AI assistant for SurveyCTO users. Like most people, we found that ad hoc and manual QA methods only got us so far, because interventions aimed at improving one type of response often have unexpected effects elsewhere. When you improve interactions A and B, interactions C, D, and E might suffer, so it can easily become a game of “one step forward, two steps back.” Without a good system for evaluation and QA, you can’t even tell when you’re making forward vs. backward progress.
I’ll start by discussing the fundamental levers of control that we use to control modern AI chatbots, then I’ll discuss the process and systems that can get us from a piloted POC to something that’s good enough to actually use in production. Finally, I’ll end with a discussion of the main lesson learned: that it’s really very hard to improve these systems, and that a rigorous system of evaluation is absolutely indispensable.
Understanding levers of control

We began our SurveyCTO AI Assistant work by evaluating several no-code options, but we didn’t feel that they offered a path to the level of quality and control that we required. First we tried Microsoft’s Copilot Studio, which was a new option for building AI assistants that wasn’t available when we’d originally started piloting AI assistance. Unfortunately, after loading it up with SurveyCTO’s documentation, website, and Support Center, informal testing revealed that response quality was not where we needed it to be, and there just weren’t levers of control that we could use to make meaningful improvements. We also built an OpenAI GPT; that was better, but still wasn’t good enough, also lacked sufficient levers of control, and would have only been available to paying ChatGPT subscribers.
While either of these no-code options would have been totally fine for a POC, they didn’t offer us the control we required to be able to manage for quality. We therefore ended up building a custom solution that leveraged the LangChain library, our experience hosting on AWS, and Microsoft’s Azure AI Search offering. This gave us all of the levers of control that have become common in production AI systems:
- Foundation model: Perhaps most fundamentally, system performance depends on our choice of foundation model provider, as well as the class and version of the model.
- Prompt engineering: The system prompt is similarly fundamental, as it provides our core instructions and guidance on desired model behavior. There are also prompt templates that frame user interactions, including how we handle conversation history and other forms of memory.
- Retrieval augmented generation (RAG): As we seek to ground our chatbot in authoritative content, we have many additional levers of control. This starts with the selection of which content to include, and then becomes extremely technical. You have: how to read and parse the content, the chunk size and overlap for dividing the content into RAG-sized pieces, how to contextualize each piece of content, which database technology to use, which indexing technology to use, which search technology to use (semantic, hybrid, knowledge graphs, other), how many matches to include, whether you have some kind of relevance threshold for inclusion, and then how to integrate matches into the user prompt (which involves more prompt engineering and, potentially, methods of summarizing content). [ If you don’t already know about RAG, learn more here and here. ]
- Guardrails: Finally, we have the safety systems that help us to sleep well at night. This includes choices of which guardrails to include, and how tightly to configure them. We might manage our own guardrails with open-source tools, or use content safety systems available from the AI model providers (like this one from Azure).
Note that even the easy stuff can become complicated. For example: the model can be very sensitive to the phrasing and even the formatting of the system prompt in unexpected ways; reading and parsing web content can become really complex and messy (does the website dynamically generate content such that simple attempts to read pages fail to capture all of the content? how do you filter out the navigation, sidebars, and footers, to focus on the real content you care about?); and even selecting content becomes complicated once stuff like outdated support articles or blog posts start leading to inaccurate chatbot responses.
And these systems are rarely static. You have new content to include over time. The model provider continuously or periodically updates the model you’re using (or, if they don’t, you’re always tempted to try new model versions, as they might be cheaper, faster, and/or better). You start somewhere, and then things change.
Finally, the most important thing is this: none of these levers of control have impacts that are purely deterministic or easily predictable. Changes in the system prompt, in particular, might have no impact at all — or a profound impact on even responses that seem entirely unrelated. The same goes for changes in the content or RAG system, or in the foundation model. The simple reality is that these are our best levers of control, but we can’t actually predict their impacts. We are therefore forced to be entirely empirical.
Building and piloting a POC
We started our SurveyCTO AI Assistant the way most people do: by taking a first stab, testing and iterating in a manual, ad hoc way, and then opening up to low-stakes piloting to essentially scale up the manual, ad hoc testing. In our case, we piloted with the internal Dobility team, with a system to collect feedback about inaccuracies and other issues.
During piloting, we captured conversations in a secure and anonymized form that would allow us to report and learn effectively. This included the standard thumbs-up/thumbs-down feedback buttons on every AI response, plus an automated qualitative analysis pipeline that would report out on themes, automatically detect cases where the user appeared frustrated or had to correct the AI assistant, and link us to specific conversations to investigate. We also reported out full conversation logs in both .csv and .pdf formats for additional review and analysis, and conducted a lot of manual review and assessment.
Two problems emerged pretty quickly:
- The volume of pilot conversations made manual review less and less practical.
- We wanted to start using our various levers of control to improve on the inaccuracies and other issues uncovered by pilot users — but the majority of responses were really great as they were, so we needed to be able to figure out which changes would improve the responses we wanted to improve without having a negative impact on the many responses that we didn’t want to change.
Developing systems for evaluation and QA
To be able to make changes to the system and evaluate their full range of impacts, we needed a more automated and scalable method of performing evaluation and QA. Here’s the system we came up with:
- Define test sets using .csv conversation logs already reported out by our system. These are just .csv files with random or nonrandom sets of conversations (e.g., a 10% random sample, or all of those within a certain date range that include any thumbs-down feedback).
- Re-run conversations in selected test sets using the latest code, content, and settings. Effectively, we’re taking each conversation that took place sometime in the past and re-running it with whatever system changes have taken place between then and now. In our case, this means re-running conversations in our development or QA environments, which are where all prospective changes in code, content, and settings are evaluated before moving forward into production use. (To protect the integrity and security of production systems, we separate our AWS systems into four separate environments split across two segregated accounts, one for development and QA and one for staging and live production.)
- Compare responses to see when, how, and to what extent the latest responses differ from the original ones. Because these models are fundamentally stochastic, we don’t expect any exact matches. Rather, we use an LLM like GPT-4 to help us compare the responses for effective equivalence, differences that a human reviewer would classify as meaningful, etc.
- Evaluate responses against various measures of quality. Here again, we need the help of an LLM like GPT-4 to grade both the original and the new responses using rubrics we define; for each rubric, we ask it to give us both a numeric 1-5 rating as well as a brief explanation (the latter of which helps when we’re evaluating the evaluator). We’ve tended to rely most on two rating scales:
- Instruction-following: We give the LLM the response, the system prompt, and a rubric that discusses how to score the response against the instructions given. Because our system prompts include all of our guidance on how the AI assistant should behave, including high-level objectives like helpfulness and truthfulness, we take the instruction-following score as a good overall rating of quality.
- Groundedness: Because one of our key goals is to ground responses in authoritative and verifiable sources, we also score every response’s “groundedness.” To facilitate this, we capture the raw content excerpts inserted into user prompts by our RAG system, and we report them alongside responses in our conversation logs (for both the original responses and the new ones we generate for evaluation). Then, when evaluating groundedness, we give the LLM both the response and the raw content excerpts, so that it can rate how grounded each response is in the excerpts it was given.
Relying on an LLM to conduct evaluations is a necessary evil here, and it presents a range of new prompt engineering challenges. But armed with comparisons, scores, and explanations of scores, we can evaluate the evaluator by conducting human expert evaluations and then comparing the human and LLM evaluations. In our case, it didn’t take long to get to LLM evaluations that were a bit noisy but generally unbiased.
Evaluating responses in multi-step conversations
One particular challenge is worth calling out: how to best evaluate multi-step (a.k.a. “multi-turn”) conversations. The problem is that system changes can alter responses in ways that fundamentally alter the course of conversations. That’s because the original human user will ask follow-up questions based on the responses they receive; if you change the responses, you change the follow-up questions — but during the automated evaluation stage you don’t have the original user available. And even if you did, how would you make an apples-to-apples comparison of responses to different follow-up questions?
The solution we settled on was to use the original conversation history at each step of a new conversation. To be very concrete:
- Conversation Step 1: use the original user prompt, from the start of the conversation, to generate a new response
- Conversation Step 2: use the original user prompt with the original conversation history (including the original response to Step 1, not the new response) to generate a new response
- Conversation Step 3: use the original user prompt with the original conversation history (which includes the original prompts and responses from Steps 1 and 2) to generate a new response
- And so on
This might seem weird, and it is. At each stage, the new system is essentially being lied to about the conversation history, because we’re discarding the new system’s earlier responses in favor of the original responses. But at each step of the conversation, we then have a clean, apples-to-apples comparison: given the same inputs (including both the user prompt and the conversation history), we get to see how the new system responds relative to the original one.
Now, you might also be thinking, “but that biases your evaluation of the new system” — and you’d be absolutely right! The original conversation history, which might include lower-quality responses and even inaccurate content, is being inserted into the new conversations, potentially dragging down the new system’s response quality.
I’ll give you an example. Early on, we discovered that some very old blog posts had pricing information that was no longer accurate, and the RAG system was sometimes picking up those posts and using them to ground inaccurate responses about SurveyCTO pricing. We then devised a system to exclude posts like these from our RAG system, but during evaluation we could see that the posts and their inaccuracies were still sometimes popping up in new responses. Looking closely, the problem was that the inaccurate pricing information was in the original conversation history, and so could creep into later (new) responses in those same conversations.
Luckily, there turns out to be a simple solution: consider the first response in each conversation, where there is no conversation history to potentially corrupt or attenuate new responses. For that first response, we get a clean apples-to-apples comparison between original and new responses, without any bias coming in via the conversation history. And indeed, when we focus our analysis on just those first responses, we see that our system changes result in responses that are markedly more different.
It’s logical to ask, then: “why not only evaluate first responses, if they give the cleanest evaluation of the new system’s performance?” For our case, my concern has been that those initial prompts are not fully representative of user queries. For example, a bunch of users start conversations with prompts like “hi!” or “what can you do for me?” They don’t get into the real meat of their substantive queries until a step or two into the conversation. So I prefer to evaluate conversations overall, and break out analysis of those first responses as a measure of potential bias. I think of it as a bounding exercise: the overall scores are something like a lower bound and the first-response scores are something closer to an upper bound.
An important lesson: Improvement is really hard!
Our biggest takeaway from our evaluation system is that improvement is dishearteningly difficult.
We culled out-of-date content, made careful tweaks to our RAG system, and made a bunch of thoughtful revisions to our system prompt. We iterated based on specific cases we were trying to improve, manually testing and re-testing those cases as we went along. While it was difficult to achieve meaningful improvements in the cases we were focused on, we eventually got there. But then we ran the whole system through a more thorough evaluation and… our average scores actually went DOWN! Heartbreaking.
We first went through the automated evaluations, of course, assuming that it was the evaluations that were flawed. (Of course we made things better rather than worse!) But no, that wasn’t it. As we’d feared, our attempts to tighten its grounding and reduce its hallucinations meant that it did a worse job logically filling gaps and combining available information in novel ways, making some responses unquestionably worse even while some improved.
After accepting that the evaluation results were at least directionally accurate, we went back to work. After more iteration — this time testing against a full test set each time — we were able to get to a place we were not too unhappy with: distinct improvements in the cases we cared most about (where users had flagged responses with thumbs-down feedback, including a number with inaccuracies), and not too much harm to responses that had been helpful. But still, the overall degree of improvement was quite modest, and there remained cases where responses definitely got worse.

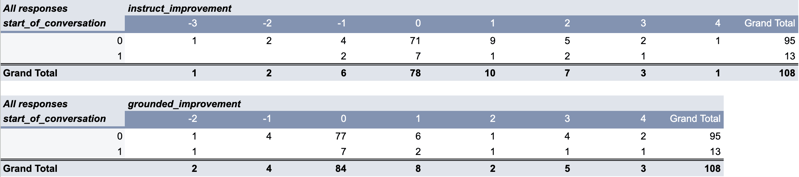
However, as discussed in the previous section, we did see that the first responses in each conversation (where we have the most unbiased evaluations) were markedly more different: 61.5% were rated as materially different and 0% were rated as effectively equivalent.

Our average degree of improvement was also higher for those first responses, which was gratifying to see.

Looking at the full distribution of results, though, there are still some cases where even the results at the start of a conversation are worse rather than better. And looking into the individual cases, it’s not just an artifact of the evaluation: we definitely made some responses worse even as we corrected and improved others.
As somebody who’s spent a lifetime building software, this has been a little bit hard for me to accept. Sure, it’s not that uncommon for a new release to include a nonzero number of “regressions” — basically, stuff you accidentally break — but I would typically not release a new version to the public as long as there were known regressions. I’ve always wanted new releases to be unambiguous improvements for all cases and for everyone. At least, I would always want to believe that at the point of release.
Here, once a rigorous evaluation system is in place, I’m confronted with the fact that unambiguous improvement is effectively unattainable. But still, I console myself: ambiguous improvement is better than no improvement at all, and it’s a whole lot better than ambiguous deterioration. And that’s exactly where I think we’d be without a good system for evaluating the impact of our changes.
<- Previous article in series: "Beating the mean: beyond chatbots"
<-- Start at the beginning: "Beating the mean: introducing the series"
Note: all screenshots by the author and all images created with OpenAI's ChatGPT (DALL-E).



Comments